
Building a Thesis-Specific AI Agent (That Tries Not to Hallucinate)
Published:
Hello there! In this post, I will write a bit about AI Agents, digressing about Patrine, my PhD Thesis Agent. You can find more details in the repo.
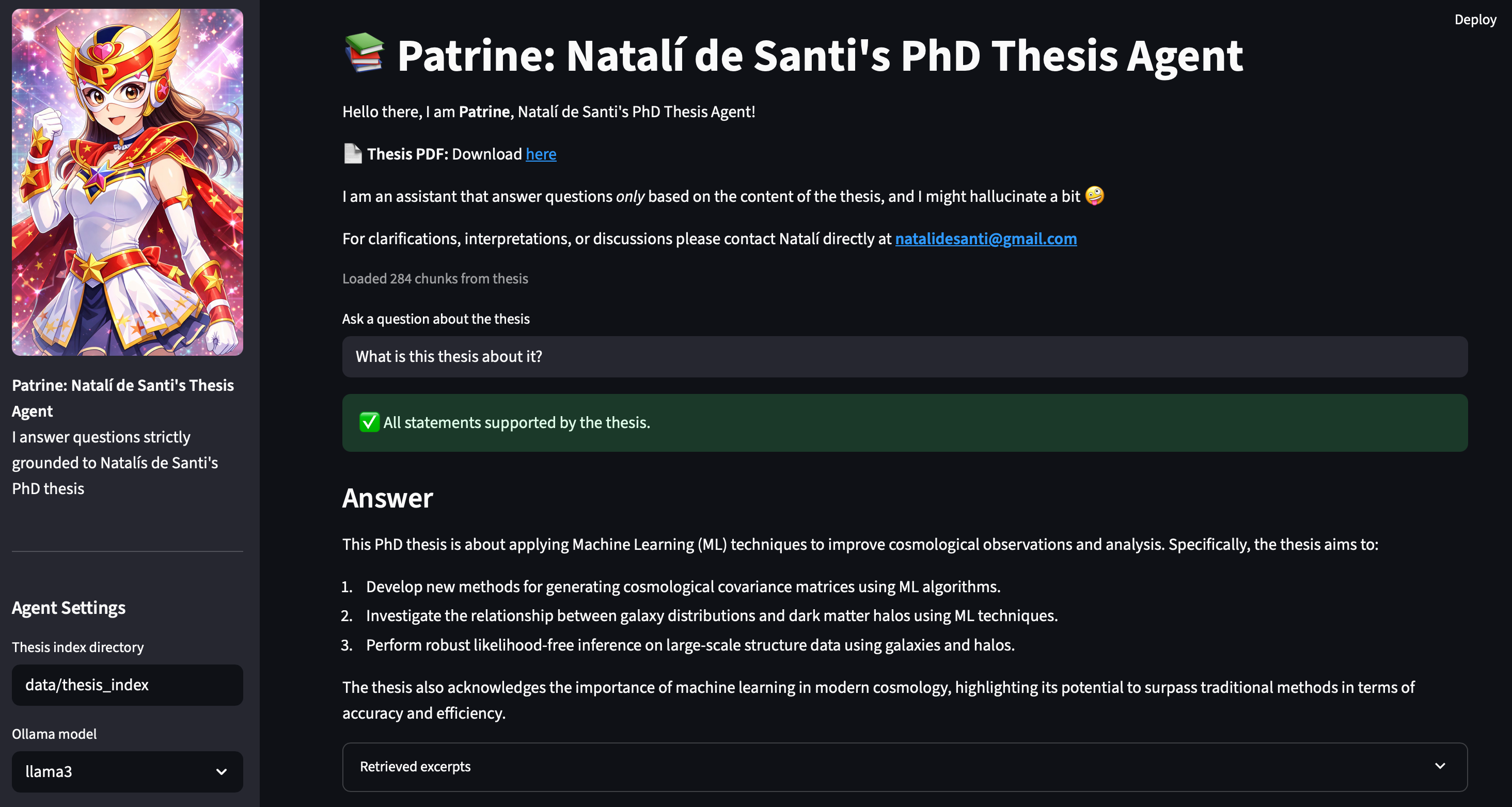
A glimpse of the streamlit app
Large Language Models (LLMs) are great at sounding confident, sometimes too confident.
Now it has been a while that I finished my PhD and I realized something ironic: even I do not remember every detail of my own thesis anymore.
So I built Patrine, a thesis-specific AI agent that answers questions only using the content of my PhD thesis, runs fully locally, and tries very hard not to hallucinate.
This post explains how it works, why I designed it this way, and what still goes wrong.
Why a thesis-specific agent?
I did not want:
- a generic PDF chatbot
- a model trained on the entire internet
- something that confidently invents explanations
I wanted:
- an assistant grounded only in my thesis
- one that can say “this is not discussed in the thesis”
- something I could run locally, without paid APIs or data uploads
This immediately rules out fine-tuning and points to a Retrieval-Augmented Generation (RAG) approach.
High-level architecture
The system has two clearly separated phases:
(1) Preprocessing (run once) Thesis PDF → chunks → embeddings → saved index
(2) Inference (interactive) Question → retrieve relevant chunks → LLM answer → optional verification
This separation is crucial:
- the thesis becomes a fixed knowledge base
- the agent cannot “learn” anything else at runtime
Step 1: One-time preprocessing
The thesis is processed once and saved to disk.
Text extraction and chunking
I use a sliding window over words to preserve context:
def sliding_window_chunks(text, window = 600, stride = 300, min_words = 50):
words = text.split()
chunks = []
for i in range(0, len(words), stride):
chunk = " ".join(words[i:i + window])
if len(chunk.split()) >= min_words:
chunks.append(chunk)
return chunks
This avoids tiny fragments while keeping overlap between chunks!
Embeddings
Each chunk is embedded using a local sentence transformer:
embedder = SentenceTransformer("all-MiniLM-L6-v2")
embeddings = embedder.encode(chunks, convert_to_numpy = True, show_progress_bar = True, normalize_embeddings = True).astype(np.float32)
The resulting files:
chunks.jsonembeddings.npyconfig.json
Together, they form the thesis index.
Step 2: Retrieval at inference time
When the user asks a question, I embed it and retrieve the most relevant chunks:
def retrieve_chunks(question, chunks, embeddings, embedder, top_k = 5):
q_emb = embedder.encode([question], convert_to_numpy = True, normalize_embeddings = True)
sims = cosine_similarity(q_emb, embeddings)[0]
idx = sims.argsort()[-top_k:][::-1]
return [chunks[i] for i in idx]
This ensures the LLM sees only thesis excerpts.
Step 3: A locked agent prompt
The most important design choice is locking the agent identity.
The model is explicitly told:
- it is trained exclusively on my thesis
- it must not use outside knowledge
- it must refuse if the answer is not present
SYSTEM_PROMPT = (
"You are an expert assistant trained exclusively on Natalí Soler Matubaro de Santi's PhD thesis."
"Use ONLY the provided thesis excerpts."
"Do NOT use external knowledge or speculation."
"If the answer is not present, say: 'This is not discussed in the thesis.'"
)
This does not eliminate hallucinations, but it reduces them a lot.
Step 4: Local LLM inference with Ollama
Everything runs locally using Ollama:
ollama_client = Client(host = "http://localhost:11434")
def generate_answer(question, context, model = "llama3"):
prompt = (SYSTEM_PROMPT + f"Thesis excerpts: {context}"
f"Question: {question} Answer:" )
response = ollama_client.generate(model = model, prompt = prompt, stream = False, options={"temperature": 0.1}
return response["response"].strip()
Lower temperature helps reduce creative gap-filling.
Step 5: Answer verification (hallucination detection)
Even with all of the above, hallucinations still happen — especially with:
- abbreviations
- implicit assumptions
- vague phrasing
To detect this, I added a verification pass that checks each sentence against the retrieved excerpts.
Conceptually:
Answer → split into sentences → verify each sentence → flag unsupported ones
This does not fix hallucinations: it surfaces them.
What still goes wrong (honestly)
Even with verification:
- small models try to “help” by filling gaps
- paraphrases can drift slightly from the text
- abbreviations with multiple meanings are a common failure mode
The advantage here is that the thesis is mine, so I can immediately tell when something is off.
This project reinforced an important lesson:
Hallucination is not just a model problem: it is a retrieval and grounding problem.
Why keep it local?
This app cannot be deployed as-is, because it requires:
- a local
Ollamaruntime - local models
That is intentional.
It gives me:
- reproducibility
- zero API dependencies
Not every AI system needs to scale!
Final thoughts
Patrine is not meant to replace reading the thesis. It is a navigation and memory aid, nothing more.
But as a small end-of-year project, it was a fun way to combine:
- ML engineering
- research rigor
- and something genuinely useful to myself
Once again, you can find the full code here: https://github.com/natalidesanti/patrine_thesis_agent